
























































































p350
This link has been bookmarked by 406 people . It was first bookmarked on 06 Jul 2010, by someone privately.
-
31 Dec 17
-
03 May 15
-
Semantic Web
-
In 2013, more than four million Webdomains contained Semantic Web markup.[7]
-
-
25 Mar 15
-
<div vocab="http://schema.org/" typeof="Person"> <span property="name">Paul Schuster</span> was born in <span property="birthPlace" typeof="Place" href="http://www.wikidata.org/entity/Q1731"> <span property="name">Dresden</span>. </span> </div>
-
-
18 Jan 15
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
-
Tim Berners-Lee calls the resulting network of Linked Data the Giant Global Graph, in contrast to the HTML-based World Wide Web. Berners-Lee posits that if the past was document sharing, the future is data sharing. His answer to the question of "how" provides three points of instruction. One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
-
Tim Berners-Lee has described the semantic web as a component of "Web 3.0"
-
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
-
-
30 Dec 14
-
20 Dec 14
 Dave Dennis
Dave Dennis"I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A "Semantic Web", which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize."
-
19 Nov 14
-
The Semantic Web is a collaborative movement led by international standards body the World Wide Web Consortium (W3C).[1] The standard promotes common data formats on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web, dominated by unstructured and semi-structured documents into a "web of data".
-
According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries"
-
it extends the network of hyperlinked human-readable web pages by inserting machine-readable metadata about pages and how they are related to each other. This enables automated agents to access the Web more intelligently and perform more tasks on behalf of users.
-
Purpose[edit]
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily. Humans are capable of using the Web to carry out tasks such as finding the German translation for "eight days", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
The Semantic Web, as originally envisioned, is a system that enables machines to "understand" and respond to complex human requests based on their meaning. Such an "understanding" requires that the relevant information sources be semantically structured.
-
Tim Berners-Lee originally expressed the vision of the Semantic Web as follows:
-
the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize.
-
Limitations of HTML[edit]
Many files on a typical computer can also be loosely divided into human readable documents and machine readable data. Documents like mail messages, reports, and brochures are read by humans. Data, like calendars, addressbooks, playlists, and spreadsheets are presented using an application program which lets them be viewed, searched and combined.
Currently, the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML), a markup convention that is used for coding a body of text interspersed with multimedia objects such as images and interactive forms. Metadata tags provide a method by which computers can categorise the content of web pages, for example:
-
<meta name="keywords" content="computing, computer studies, computer" /> <meta name="description" content="Cheap widgets for sale" /> <meta name="author" content="John Doe" />
-
There is no way to say "this is a catalog" or even to establish that "Acme Gizmo" is a kind of title or that "
-
€199" is a price
-
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
-
- Vastness: The World Wide Web contains many billions of pages. The SNOMED CT medical terminology ontology alone contains 370,000 class names, and existing technology has not yet been able to eliminate all semantically duplicated terms. Any automated reasoning system will have to deal with truly huge inputs.
- Vagueness: These are imprecise concepts like "young" or "tall". This arises from the vagueness of user queries, of concepts represented by content providers, of matching query terms to provider terms and of trying to combine different knowledge bases with overlapping but subtly different concepts. Fuzzy logic is the most common technique for dealing with vagueness.
- Uncertainty: These are precise concepts with uncertain values. For example, a patient might present a set of symptoms which correspond to a number of different distinct diagnoses each with a different probability. Probabilistic reasoning techniques are generally employed to address uncertainty.
- Inconsistency: These are logical contradictions which will inevitably arise during the development of large ontologies, and when ontologies from separate sources are combined. Deductive reasoning fails catastrophically when faced with inconsistency, because "anything follows from a contradiction". Defeasible reasoning and paraconsistent reasoning are two techniques which can be employed to deal with inconsistency.
- Deceit: This is when the producer of the information is intentionally misleading the consumer of the information. Cryptography techniques are currently utilized to alleviate this threat.
Challenges[edit]
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
-
Well-established standards:
-
- XML
- RDF
- RDFS
- SPARQL
- Web Ontology Language (OWL)
- Rule Interchange Format (RIF)
-
Skeptical reactions[edit]
Practical feasibility
-
Cory Doctorow's critique ("metacrap") is from the perspective of human behavior and personal preferences. For example, people may include spurious metadata into Web pages in an attempt to mislead Semantic Web engines that naively assume the metadata's veracity. This phenomenon was well-known with metatags that fooled the Altavista ranking algorithm into elevating the ranking of certain Web pages: the Google indexing engine specifically looks for such attempts at manipulation.
-
Censorship and privacy
-
An advanced implementation of the semantic web would make it much easier for governments to control the viewing and creation of online information, as this information would be much easier for an automated content-blocking machine to understand. In addition, the issue has also been raised that, with the use of FOAF files and geolocation meta-data, there would be very little anonymity associated with the authorship of articles on things such as a personal blog.
-
Doubling output formats
-
Another criticism of the semantic web is that it would be much more time-consuming to create and publish content because there would need to be two formats for one piece of data: one for human viewing and one for machines
-
Another argument in defense of the feasibility of semantic web is the likely falling price of human intelligence tasks in digital labor markets, such as Amazon's Mechanical Turk.
-
-
26 Oct 14
-
23 Oct 14
-
Semantic Network Model
-
machines to "understand" and respond to complex human requests based on their meaning
-
"emphasis"
-
Microformats extend HTML syntax to create machine-readable semantic markup about objects including people, organisations, events and products
-
TML describes documents and the links between them. RDF, OWL, and XML
-
-
19 Sep 14
-
10 Sep 14
-
erman translation for "eight days", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
-
04 Sep 14
-
According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries".[2] The term was coined by Tim Berners-Lee for a web of data that can be processed by machines.[3]
-
-
02 Jun 14
-
23 May 14
-
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries
-
enabling users to find, share, and combine information more easily
-
machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines
-
-
20 May 14
-
he standard promotes common data formats on the World Wide Web
-
he Semantic Web aims at converting the current web, dominated by unstructured and semi-structured documents into a "web of data".
-
for a web of data that can be processed by machines
-
Web by enabling users to find, share, and combine information more easily.
-
However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines.
-
The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
-
RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
-
-
19 Apr 14
-
The Semantic Web is a collaborative movement led by international standards body the World Wide Web Consortium (W3C).[1] The standard promotes common data formats on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web, dominated by unstructured and semi-structured documents into a "web of data". The Semantic Web stack builds on the W3C's Resource Description Framework (RDF).[2]
-
It extends the network of hyperlinked human-readable web pages by inserting machine-readable metadata about pages and how they are related to each other, enabling automated agents to access the Web more intelligently and perform tasks on behalf of users.
-
a web of data that can be processed directly and indirectly by machines."
-
The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
-
-
27 Mar 14
-
-
"The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries."[2] The term was coined by Tim Berners-Lee for a web of data that can be processed by machines.
-
. Humans are capable of using the Web to carry out tasks such as finding the Estonian translation for "twelve months", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
-
27 Feb 14
-
Tim Berners-Lee
-
-
20 Feb 14
-
04 Feb 14
-
03 Jan 14
-
Wide Web Consortium (W3C)
-
-
10 Dec 13
-
03 Dec 13
-
23 Nov 13
-
10 Nov 13
-
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries
-
The concept of the Semantic Network Model was formed in the early sixties by the cognitive scientist Allan M. Collins, linguist M. Ross Quillian and psychologist Elizabeth F. Loftus in various publications,[7][8][9][10][11] as a form to represent semantically structured knowledge.
-
The term "Semantic Web" was coined by Tim Berners-Lee,[3]
-
Semantic Web standards. He defines the Semantic Web as "a web of data that can be processed directly and indirectly by machines.
-
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily.
-
However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A "Semantic Web", which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize.
-
Projects
-
-
28 Sep 13
-
22 Sep 13
-
specifying the semantics of objects such as items for sale or prices.
-
extend HTML syntax to create machine-readable semantic markup about objects including people, organisations, events and products
-
HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
-
technologies that provide a formal description of concepts, terms, and relationships
-
Documents "marked up" with semantic information (an extension of the HTML <meta> tags used in today's Web pages to supply information for Web search engines using web crawlers). This could be machine-understandable information about the human-understandable content of the document (such as the creator, title, description, etc.) or it could be purely metadata representing a set of facts (such as resources and services elsewhere on the site). Note that anything that can be identified with a Uniform Resource Identifier (URI) can be described, so the semantic web can reason about animals, people, places, ideas, etc. Semantic markup is often generated automatically, rather than manually.
-
-
19 Aug 13
-
03 Aug 13
-
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries
-
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily.
-
The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
system that enables machines to "understand" and respond to complex human requests based on their meaning. Such an "understanding" requires that the relevant information sources be semantically structured.
-
It has applications in publishing, blogging, and many other areas.
-
The architectural model proposed by Tim Berners-Lee is used as basis to present a status model that reflects current and emerging technologies
-
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
-
descriptive data stored in Web-accessible databases,
-
Extensible HTML (XHTML) in
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
-
Berners-Lee posits that if the past was document sharing, the future is data sharing. His answer to the question of "how" provides three points of instruction. One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
-
access to a semantic Web integrated across a huge space of data, you'll have access to an unbelievable data resource ...
-
Probabilistic reasoning techniques are generally employed to address uncertainty.
-
This list of challenges is illustrative rather than exhaustive, and it focuses on the challenges to the "unifying logic" and "proof" layers of the Semantic Web. The World Wide Web Consortium (W3C) Incubator Group for Uncertainty Reasoning for the World Wide Web (URW3-XG) final report lumps these problems together under the single heading of "uncertainty". Many of the techniques mentioned here will require extensions to the Web Ontology Language (OWL) for example to annotate conditional probabilities.
-
- Resource Description Framework (RDF), a general method for describing information
- RDF Schema (RDFS)
- Simple Knowledge Organization System (SKOS)
- SPARQL, an RDF query language
- Notation3 (N3), designed with human-readability in mind
- N-Triples, a format for storing and transmitting data
- Turtle (Terse RDF Triple Language)
- Web Ontology Language (OWL), a family of knowledge representation languages
- Rule Interchange Format (RIF), a framework of web rule language dialects supporting rule interchange on the Web
-
-
Documents "marked up" with semantic information (an extension of the HTML <meta> tags used in today's Web pages to supply information for Web search engines using web crawlers). This could be machine-understandable information about the human-understandable content of the document (such as the creator, title, description, etc.) or it could be purely metadata representing a set of facts (such as resources and services elsewhere on the site). Note that anything that can be identified with a Uniform Resource Identifier (URI) can be described, so the semantic web can reason about animals, people, places, ideas, etc. Semantic markup is often generated automatically, rather than manually.
-
Doubling output formats[edit source | editbeta]
Another criticism of the semantic web is that it would be much more time-consuming to create and publish content because there would need to be two formats for one piece of data: one for human viewing and one for machines. However, many web applications in development are addressing this issue by creating a machine-readable format upon the publishing of data or the request of a machine for such data. The development of microformats has been one reaction to this kind of criticism. Another argument in defense of the feasibility of semantic web is the likely falling price of human intelligence tasks in digital labor markets, such as the Amazon Mechanical Turk.
Specifications such as eRDF and RDFa allow arbitrary RDF data to be embedded in HTML pages. The GRDDL (Gleaning Resource Descriptions from Dialects of Language) mechanism allows existing material (including microformats) to be automatically interpreted as RDF, so publishers only need to use a single format, such as HTML.
-
A popular vocabulary on the semantic web is Friend of a Friend (or FOAF), which uses RDF to describe the relationships people have to other people and the "things" around them. FOAF permits intelligent agents to make sense of the thousands of connections people have with each other, their jobs and the items important to their lives;[33] connections that may or may not be enumerated in searches using traditional web search engines. Because the connections are so vast in number, human interpretation of the information may not be the best way of analyzing them.
FOAF is an example of how the Semantic Web attempts to make use of the relationships within a social context.
-
Nextbio is accessible via a search engine interface.
-
-
25 Jun 13
-
02 May 13
-
The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedio
-
-
30 Apr 13
-
25 Apr 13
-
05 Mar 13
-
07 Jan 13
-
11 Dec 12
-
Semantic Web
-
The standard promotes common data formats on the World Wide Web.
-
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily.
-
Limitations of HTML
-
Documents like mail messages, reports, and brochures are read by humans. Data, like calendars, addressbooks, playlists, and spreadsheets are presented using an application program which lets them be viewed, searched and combined in different ways.
-
Currently, the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML),
-
one can create and present a page that lists items for sale.
-
With HTML and a tool to render it
-
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
-
-
08 Dec 12
-
29 Oct 12
 Hayden Jeter
Hayden JeterThe Semantic Web is a collaborative movement led by the international standards body, the World Wide Web Consortium (W3C).[1] The standard promotes common data formats on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web dominated by unstructured and semi-structured documents into a "web of data". The Semantic Web stack builds on the W3C's Resource Description Framework (RDF).[2]
-
16 Oct 12
-
18 Aug 12
-
09 Aug 12
-
16 Jul 12
-
collaborative movement
-
common formats for data
-
web of data
-
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries
-
Semantic Web as "a web of data that can be processed directly and indirectly by machines."
-
It extends the network of hyperlinked human-readable web pages by inserting machine-readable metadata about pages and how they are related to each other, enabling automated agents to access the Web more intelligently and perform tasks on behalf of users
-
a form to represent semantically structured knowledge
-
a web of data that can be processed directly and indirectly by machines."
-
evolution of the current Web by enabling users to find, share, and combine information more easily
-
The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
machines cannot accomplish all of these tasks without human direction
-
system that enables machines to "understand" and respond to complex human requests based on their meaning
-
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers
-
but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines
-
integrator
-
Documents
-
Data,
-
Currently, the World Wide Web is based mainly on documents
-
Metadata tags provide a method by which computers can categorise the content of web pages
-
markup following intention, rather than specifying layout details directly
-
But this practice falls short of specifying the semantics of objects such as items for sale or prices.
-
provide descriptions that supplement or replace the content of Web documents
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content
-
can process knowledge itself, instead of text
-
if the past was document sharing, the future is data sharing
-
the resulting network of Linked Data the Giant Global Graph
-
huge space of data
-
Vastness
-
Vagueness
-
imprecise concepts
-
precise concepts with uncertain values
-
Uncertainty
-
Inconsistency
-
contradictions
-
Deceit
-
content structure within documents
-
from the perspective of human behavior and personal preferences
-
manipulation
-
geo location
-
two formats
-
much more time-consuming to create and publish content
-
-
12 Jul 12

-
06 Jul 12
-
09 Jun 12
-
Semantic Web aims at converting the current web of unstructured documents[clarification needed] into a "web of data"
-
Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries
-
term was coined by Tim Berners-Lee
-
applications in industry, biology and human sciences research have already proven the validity of the original concept.
-
main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easil
-
Humans are capable of using the Web to carry out tasks such as finding the Irish word for "folder", reserving a library book, and searching for the lowest price for a DVD
-
However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines
-
-
06 May 12
-
enabling automated agents to access the Web more intelligently and perform tasks on behalf of users.
-
machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines.
-
so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
deceit
-
-
05 May 12
-
30 Apr 12
-
24 Apr 12
-
11 Apr 12
-
09 Apr 12
-
The Semantic Web is a collaborative movement led by the World Wide Web Consortium (W3C)[1] that promotes common formats for data on the World Wide Web
-
aims at converting the current web of unstructured documents into a "web of data"
-
"The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries."
-
However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines.
-
The semantic web is a vision of information that can be readily interpreted by machines
-
"understanding" requires that the relevant information sources is semantically structured, a challenging task.
-
HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts.
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content.
-
In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
-
Berners-Lee posits that if the past was document sharing, the future is data sharing. His answer to the question of "how" provides three points of instruction. One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
-
Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
-
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit.
-
-
30 Mar 12
-
10 Mar 12
-
The Semantic Web is a collaborative movement led by the World Wide Web Consortium (W3C) [1] that promotes common formats for data on the World Wide Web
-
By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web of unstructured documents into a "web of data". It builds on the W3C's Resource Description Framework (RDF).[2]
According to the W3C, "The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries.
-
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily. Humans are capable of using the Web to carry out tasks such as finding the Irish word for "folder", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
-
-
28 Feb 12

-
The Semantic Web is a collaborative movement led by the World Wide Web Consortium (W3C) [1] that promotes common formats for data on the World Wide Web.
-
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily. Humans are capable of using the Web to carry out tasks such as finding the Irish word for "folder", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
The Semantic Web, as originally envisioned, is a system that enables machines to "understand" and respond to complex human requests based on their meaning. Such an "understanding" requires that the relevant information sources is semantically structured, a challenging task.
Tim Berners-Lee originally expressed the vision of the Semantic Web as follows:[10]
-
-
24 Jan 12
-
The Semantic Web, as originally envisioned, is a system that enables machines to "understand" and respond to complex human requests based on their meaning. Such an "understanding" requires that the relevant information sources is semantically structured, a challenging task.
-
In a paper presented by Gerber, Barnard and Van der Merwe[10] the Semantic Web landscape is charted and a brief summary of related terms and enabling technologies is presented.
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content.
-
-
20 Dec 11
-
13 Dec 11
 adrian warren
adrian warrencite for assignment 2 wk 3
-
07 Dec 11
-
05 Dec 11
-
26 Nov 11
-
Tim Berners-Lee calls the resulting network of Linked Data the Giant Global Graph, in contrast to the HTML-based World Wide Web. Berners-Lee posits that if past was document sharing, the future is data sharing. His answer to the question of "how" provides three points of instruction. One, a URL should point to the data. Two, anyone accessing the URL should get data back. Three, relationships in the data should point to additional URLs with data.
-
The concept of the Semantic Network Model was coined in the early sixties by the cognitive scientist Allan M. Collins, linguist M. Ross Quillian and psychologist Elizabeth F. Loftus in various publications,[5][6][7][8][8] as a form to represent semantically structured knowledge. It extends the network of hyperlinked human-readable web pages by inserting machine-readable metadata about pages and how they are related to each other, enabling automated agents to access the Web more intelligently and perform tasks on behalf of users.
-
The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily. Humans are capable of using the Web to carry out tasks such as finding the Irish word for "folder", reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
The Semantic Web, as originally envisioned, is a system that enables machines to "understand" and respond to complex human requests based on their meaning. Such an "understanding" requires that the relevant information sources is semantically structured, a challenging task.
-
Tim Berners-Lee originally expressed the vision of the Semantic Web as follows:[10]
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘Semantic Web’, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.
-
With HTML and a tool to render it (perhaps web browser software, perhaps another user agent), one can create and present a page that lists items for sale. The HTML of this catalog page can make simple, document-level assertions such as "this document's title is 'Widget Superstore'", but there is no capability within the HTML itself to assert unambiguously that, for example, item number X586172 is an Acme Gizmo with a retail price of €199, or that it is a consumer product. Rather, HTML can only say that the span of text "X586172" is something that should be positioned near "Acme Gizmo" and "€199", etc. There is no way to say "this is a catalog" or even to establish that "Acme Gizmo" is a kind of title or that "€199" is a price. There is also no way to express that these pieces of information are bound together in describing a discrete item, distinct from other items perhaps listed on the page
-
-
19 Nov 11
-
06 Nov 11
-
a system that enables machines to understand and respond to complex human requests based on their meaning
-
an integrator across different content, information applications and systems
-
-
03 Oct 11
-
13 Sep 11
 Tero Toivanen
Tero ToivanenTässä vielä linkki semanttisesta web:stä wikipediasta (englanniksi, suomenkielinen versio oli aika tynkä).
semanticweb web semantic wikipedia web2.0 web3.0 reference semantic_web semanttinen
-
The Semantic Web as originally envisioned is a system that enables machines to understand and respond to complex human requests based on their meaning.
-
-
30 Jun 11
-
Furthermore, there is confusion with regard to the current status of the enabling technologies envisioned to realise the Semantic Web.
-
For example, Conrad Wolfram, has argued that Web 3.0 is where "the computer is generating new information", rather than humans.[10]
-
Given the same time frame, this next transition will not be complete until around the year 2015.
-
-
23 Jun 11
-
11 May 11
-
21 Apr 11
-
-
hyperlinked human-readable web pages
-
y inserting machine-readable metadata about pages and how they are related to each other
-
nd director of the World Wide Web Consortium
-
oversees the development of proposed Semantic Web standards
-
"a web of data that can be processed directly and indirectly by machines."
-
the formats and technologies that enable it
-
RDF Schema (RDFS)
-
e Web Ontology Language (OWL)
-
-
scientific research or data exchange among businesses
-
based on their meaning,
-
web pages are designed to be read by people, not machines
-
a vision
-
more of the tedious work
-
nformation that can be interpreted by machines
-
apable of analyzing all the data on the Web
-
machines talking to machines
-
n integrator across different content
-
a vast landscape
-
real-time publishing
-
sharing of experimental data on the Internet
-
tag their entries with topics
-
Documents like mail messages, reports, and brochures are read by humans
-
calendars, addressbooks, playlists, and spreadsheets are presented using an application program which lets them be viewed, searched and combined in many ways
-
the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML)
-
another user agent)
-
a tool to render it
-
his is a catalog
-
is a price
-
kind of title
-
Semantic HTML
-
n languages specifically designed for data
-
can describe arbitrary things such as people, meetings, or airplane parts
-
documents and the links
-
n contrast to the HTML-based World Wide Web
-
layout or rendering cues stored separately
-
can process knowledge itself, instead of text,
-
-
23 Mar 11
-
22 Mar 11
-
10 Mar 11
 Tom March
Tom March"I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘Semantic Web’, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize."
-
21 Feb 11
-
10 Feb 11
 s. farooq razvi
s. farooq razvisocial socialweb web2.0 web media term terms definition definitions concept concepts themes wiki wikipedia article info information interesting cool fascinating internet knowledge terminology talk toexplore toread server search reference contextual research semantic semanticweb technology tech engine engines method methods methodology semantics word sense database data databases searchable tosearch meaning meaningful
social socialweb web2.0 web media term terms definition definitions concept concepts themes wiki wikipedia article info information interesting cool fascinating internet knowledge terminology talk toexplore toread server search reference contextual resear
-
21 Dec 10
-
02 Dec 10
-
01 Dec 10
-
18 Nov 10
-
15 Nov 10
-
31 Oct 10
-
22 Oct 10
-
27 Sep 10
-
Semantic Web is a group of methods and technologies to allow machines to understand the meaning - or "semantics" - of information on the World Wide Web.[1]
-
-
31 Aug 10
-
27 Aug 10
-
21 Aug 10
 Dante-Gabryell Monson
Dante-Gabryell MonsonIt describes methods and technologies to allow machines to understand the meaning - or "semantics" - of information on the World Wide Web.
design semanticweb semantics metadata ontology rdf language web2.0 referencemaps
-
21 Jul 10
-
Any automated reasoning system will have to deal with truly huge inputs
-
-
17 Jul 10
-
16 Jun 10
-
01 Jun 10
-
30 May 10
-
23 May 10
-
17 May 10
-
29 Apr 10
-
16 Apr 10
-
05 Apr 10
-
Humans are capable of using the Web to carry out tasks such as finding the Finnish word for "fish", reserving a library book, and searching for a low price for a DVD. However, one computer cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that is understandable by computers, so computers can perform more of the tedious work involved in finding, combining, and acting upon information on the we
-
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘Semantic Web’, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.
– Tim Berners-Lee, 1999
-
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts. Tim Berners-Lee calls the resulting network of Linked Data the Giant Global Graph, in contrast to the HTML-based World Wide Web.
-
These technologies are combined in order to provide descriptions that supplement or replace the content of Web documents. Thus, content may manifest itself as descriptive data stored in Web-accessible databases [10], or as markup within documents (particularly, in Extensible HTML (XHTML) interspersed with XML, or, more often, purely in XML, with layout or rendering cues stored separately).
-
The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
-
RDF is a simple language for expressing data models, which refer to objects ("resources") and their relationships. An RDF-based model can be represented in XML syntax.
-
- Vastness: The World Wide Web contains at least 48 billion pages as of this writing (August 2, 2009). The SNOMED CT medical terminology ontology contains 370,000 class names, and existing technology has not yet been able to eliminate all semantically duplicated terms. Any automated reasoning system will have to deal with truly huge inputs.
- Vagueness: These are imprecise concepts like "young" or "tall". This arises from the vagueness of user queries, of concepts represented by content providers, of matching query terms to provider terms and of trying to combine different knowledge bases with overlapping but subtly different concepts. Fuzzy logic is the most common technique for dealing with vagueness.
- Uncertainty: These are precise concepts with uncertain values. For example, a patient might present a set of symptoms which correspond to a number of different distinct diagnoses each with a different probability. Probabilistic reasoning techniques are generally employed to address uncertainty.
- Inconsistency: These are logical contradictions which will inevitably arise during the development of large ontologies, and when ontologies from separate sources are combined. Deductive reasoning fails catastrophically when faced with inconsistency, because "anything follows from a contradiction". Defeasible reasoning and paraconsistent reasoning are two techniques which can be employed to deal with inconsistency.
- Deceit: This is when the producer of the information is intentionally misleading the consumer of the information. Cryptography techniques are currently utilized to alleviate this threat.
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
-
DBpedia
DBpedia is an effort to publish structured data extracted from Wikipedia: the data is published in RDF and made available on the Web for use under the GNU Free Documentation License, thus allowing Semantic Web agents to provide inferencing and advanced querying over the Wikipedia-derived dataset and facilitating interlinking, re-use and extension in other data-sources.
[edit]
-
FOAF
A popular application of the semantic web is Friend of a Friend (or FoaF), which uses RDF to describe the relationships people have to other people and the "things" around them. FOAF permits intelligent agents to make sense of the thousands of connections people have with each other, their jobs and the items important to their lives; connections that may or may not be enumerated in searches using traditional web search engines. Because the connections are so vast in number, human interpretation of the information may not be the best way of analyzing them.
FOAF is an example of how the Semantic Web attempts to make use of the relationships within a social context.
-
-
01 Apr 10
-
31 Mar 10
-
Add Sticky Note
- It needs additional references or sources for verification. Tagged since November 2009.
- Its tone or style may not be appropriate for Wikipedia. Tagged since November 2009.
- It reads like a personal reflection or essay. Tagged since November 2009.
- It may require general cleanup to meet Wikipedia's quality standards. Tagged since November 2009.
Semantic Web
From Wikipedia, the free encyclopedia
Jump to: navigation, search This article has multiple issues. Please help improve the article or discuss these issues on the talk page.
This article has multiple issues. Please help improve the article or discuss these issues on the talk page.
It has been suggested that Rule Interchange Format be merged into this article or section. (Discuss) It has been suggested that Semantic publishing be merged into this article or section. (Discuss)  W3C's Semantic Web logo
W3C's Semantic Web logo
The Semantic Web is an evolving development of the World Wide Web in which the meaning (semantics) of information and services on the web is defined, making it possible for the web to "understand" and satisfy the requests of people and machines to use the web content.[1][2] It derives from World Wide Web Consortium director Sir Tim Berners-Lee's vision of the Web as a universal medium for data, information, and knowledge exchange.[3]
-
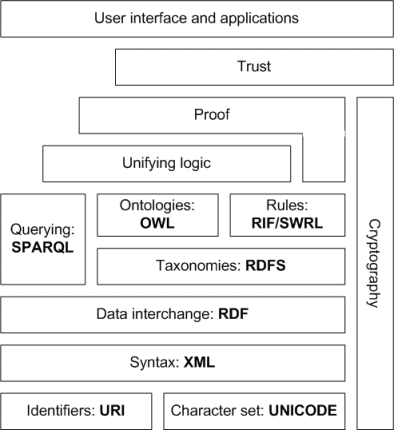 The Semantic Web Stack.
The Semantic Web Stack.
-

Public Stiky Notes
Page Comments
Would you like to comment?
Join Diigo for a free account, or sign in if you are already a member.